[k8s] CronJob이란?

Application을 운용하면서 일정 시간마다 작업을 해야할 필요성이 있다. ex) n개월이 지난 개인정보의 삭제, 조근 점검의 자동화, 이메일 보내기 이러한 작업을 사람이 해도 되겠지만 이런 귀찮은 작업을 자동화 하는 것이 개발자가 아닐까?
쿠버네티스에서도 이러한 반복작업을 자동화 할 수 있게 유닉스 계열 기반 Cronjob이라는 리소스를 지원한다.
반복 일정에 따른 Job을 만드는 Cronjob은 kube-controller-manager 시간대를 기반으로 job을 만들고 실행한다.
스케줄링 형식
Cronjob 또한 리눅스의 cron 표현식과 동일한 형식을 적용하는데 분 시 일 월 요일로 이루어져 있는데 만약 */5 * * * *로 표현된다면, 매 5분마다 1회 실행으로 적용이 된다. 0 12 * * 1로 표시된다면 매주 월요일에 정오 12시에 실행된다.
Q. 매일 오전 8시에 배치 작업을 돌게 할려면 ? -> 0 8 * * * 0 분 8시 매일 매월 매요일
CronJob YAML
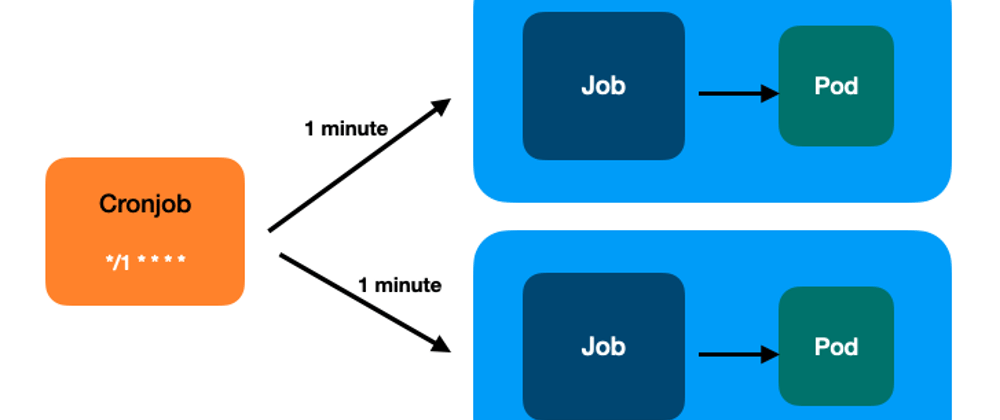
1분마다 실행되는 CronJob
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello-cron
spec:
schedule: "*/1 * * * *" # 매 1분마다 실행
startingDeadlineSeconds: 5
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["echo", "Hello, CronJob!"]
restartPolicy: OnFailure
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
concurrencyPolicy: Forbid
히스토리 여기서 successfulJobsHistoryLimit의 경우 만약 Job이 성공했다면 그 이력 pod를 얼마나 남길지를 결정한다. failedJobsHistoryLimit의 경우 실패한 작업 1개까지기록을 유지하도록 설정되어 있다.
병행성 concurrencyPolicy의 경우 병렬 실행 정책으로 위 예제의 경우 새 작업이 실행될 때 이전의 job이 끝나야한다고 표시되어 있다.
재시도 정책 restartPolicy는 pod가 실패했을 때재 시도 정책을 담당하는데 각 값에 따라 다르게 동작한다.
- Always 컨테이너가 종료시 항상 다시 시도함 (기본 값)
- OnFailure: 컨테이너의 비 정상 종료시(0이 아닌 종료 카드) 다시 시도함
- Never: 컨테이너가 종료되면 절대 다시 시작하지 않음
제한 자동으로 돌아가는 CronJob의 경우 무수히 많은 job이 생성 될 수 있다. (Job의 폭주)
특히 네트워크 지연의 경우 그동안 밀려있던 Job이 한번에 생성될 수 있는데 Job이 어떠한 이유로 인해 n초 이상 실행되지 못하면 해당 job을 포기하도록 설정할 수 있는데 이는 startingDeadlineSeconds를 통해 관리한다.
위의 예제 같은 경우 해당 스케줄된 시간보다 5초 이상 지연시 해당 job은 포기하는 식으로 네트워크 지연으로 인한 job의 폭주를 방지하고 있다.
Cronjob도 volume mount가 된다 -> 비밀 저장소 등을 통해 데이터 마운트 가능!
결론 CronJob을 통해 업무 자동화를 달성하고 조근 점검 및 야근을 피하자!