[CKA] 컨테이너 운영

컨테이너 모니터링
클러스터 운영에 있어 리소스 사용량 또는 문제 해결을 위해 모니터링을 사용할 경우가 있다. kubernetes는 이러한 모니터링을 지원하기 위해 경량 모니터링 도구(Metrics Server)를 지원하는데 kubectl top명령어를 사용하게 해준다.
설치 여부 확인
1
kubectl get deployment metrics-server -n kube-system
Metric Server를 사용해 node나 pod의 메모리, CPU 사용량 등을 확인할 수 있다.
1
2
3
4
kubectl top node # 노드들의 CPU, 메모리 사용량 확인
kubectl top pod --all-namespaces # 모든 파드의 사용량 확인
kubectl describe pod <pod-name> # 파드 상세 정보 (이벤트, 상태 등 포함)
kubectl get events # 클러스터 이벤트 확인 (CrashLoopBackOff 등)
이러한 경량 모니터링 도구이외에도 프로메테우스(오픈소스 모니터링툴), Grafana(프로메테우스의 시각화 툴) 등이 있다.
k8s 배포
Rolling Update
기존의 pod를 종료하고 새로운 pod를 생성하며 배포하는 무중단 배포를 위해 사용되는 개념
설정 yaml
1
2
3
4
5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
maxSurge는 새 버전의 pod를 몇 개까지 더 추가할지를 뜻하며, maxUnavailable은 롤링 업데이트 중 사용할 수 없는 pod가 몇개인지를 설정한다.
Rollback
최근 변경된 Deploy를 이전버전으로 되돌리는 작업으로 rollout을 통해 배포 실패나 장애 발생시 유용하다.
1
kubectl rollout undo deployment myapp-deployment
만약 특정 revision으로 돌아가고 싶다면
1
kubectl rollout undo deployment myapp-deployment --to-revision=2
으로 특정 리비전으로 돌아갈 수 있다.
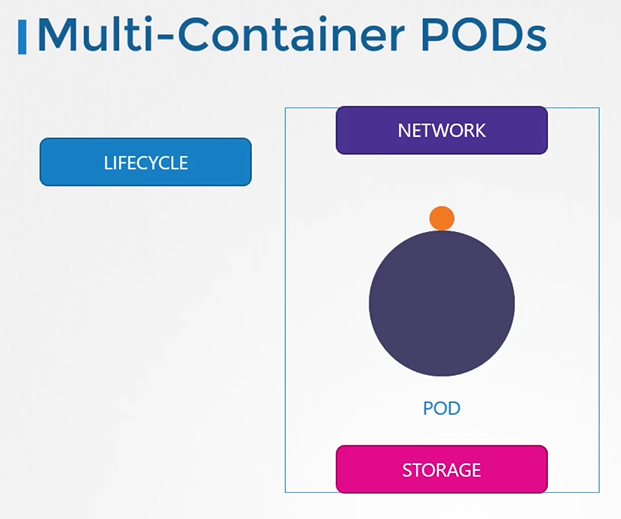
Multi-Container pod
하나의 pod안에 둘 이상의 컨테이너가 존재하는 multi-container pod는 하나의 컨테이너 life cycle과 자원을 공유한다.
이런 방식은 Sidecar(보조 컨테이너 로그, 프록시), Adapter(데이터 변환)의 패턴에서 주로 사용된다.
Multi-Conatiner yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
apiVersion: v1
kind: Pod
metadata:
name: multi-container-pod
spec:
volumes:
- name: shared-logs
emptyDir: {} # 공유 스토리지
containers:
- name: main-app
image: nginx
volumeMounts:
- name: shared-logs
mountPath: /usr/share/nginx/html
- name: log-writer
image: busybox
command: ["sh", "-c", "while true; do echo hello >> /logs/hello.txt; sleep 5; done"]
volumeMounts:
- name: shared-logs
mountPath: /logs
여기서 추가된 emptyDir는 컨테이너 간의 파일 공유에 사용되며 각 컨테이너는 localhost를 통해 내부적으로 통신이 가능하다.
Probe
살아있어요? 컨테이너씨
kubernetes에서 컨테이너의 상태를 체크하기 위해 사용되는 개념으로 HTTP GET (특정 URL 접근)방식이나 TCP Socket (특정 포트 연결 테스트) 같은 방식으로 컨테이너의 health를 체크한다.
컨테이너가 가지고 있을 수 있는 상태는 총 3가지인데 아래 표와 같이 크게 정리된다.
| Probe 종류 | 목적 | 실패 시 동작 |
|---|---|---|
| Liveness Probe | “살아있냐?” 확인 | 실패하면 컨테이너를 재시작 |
| Readiness Probe | “트래픽 받을 준비 됐냐?” 확인 | 실패하면 트래픽을 안 보냄 (Pod는 Running이어도 Ready 아님) |
| Startup Probe | “앱 시작됐냐?” 확인 (초기 부팅 오래 걸리는 앱용) | 실패하면 컨테이너를 재시작 |
Liveness Probe
컨테이너가 무한 루프 등을 통해무응답 상태에 빠졌을 경우 컨테이너가 죽었다고 판단하여 재시작 정책을 시도한다.
1
2
3
4
5
6
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
/healthz를 8080포트 최초 시작 5초후 호출하며 10초 간격으로 체크한다.
Readiness Probe
컨테이너가 준비되었을 때 Service 엔드포인트에 등록하고 만약 컨테이너가 적절하게 준비되지 않았다면, 등록하지 않아 Service가 애초에 트래픽을 보내지 않게 한다.
1
2
3
4
5
6
7
readinessProbe:
exec:
command:
- cat
- /tmp/ready
initialDelaySeconds: 5
periodSeconds: 5
/tmp/ready 파일이 존재하면 준비된 것으로 간주한다.
Startup Probe
일부 컨테이너에서는 어플리케이션이 느리게 기동될 수도 있다. 이럴 경우 시작이 완료되기전 까지 Liveness/Readiness Probe를 무시한다.
1
2
3
4
5
6
startupProbe:
httpGet:
path: /startup
port: 8080
failureThreshold: 30
periodSeconds: 10
/startup을 호출하는데 30번 실패하면 컨테이너가 죽었다고 판단한다.
k8s Upgrade
k8s cluster를 업그레이드 하는데 있어, 다양한 환경에 따라 방법이 달라진다.

- GCP를 사용한다면 쉽고 빠르고 간편하다! (안알아봄)
- kubeadm을 사용하기(배운 것)
- 혼자 하기(현재 수준이 아님)
일반적으로 GCP를 사용하거나, kubeadm을 사용하여 업그레이드 한다고 한다.
CKA 시험 및 순수 k8s 환경에서 주로 사용하는 kubeadm을 활용한 업그레이드에 대해 알아보자.
Master Node 업그레이드 하기
MasterNode에는 서비스에 기동되는 pod가 존재하지 않는다. 비록 controlplane같은 관리형 pod가 존재하지만 이런건 사소하다.
1
2
3
4
$ kubectl drain master --ignore-daemonsets --force
$ apt-get upgrade -y kubeadm=1.13.0-00
$ apt-get upgrade kubelet=1.32.0-00
$ systemctl restart kubelet
kubeadm과 kubelet을 업그레이드 함으로써 master Node의 업그레이드가 완료되었다.
Master Node에서 drain을 해야하는 이유? Node를 업그레이드하면서 kubelet을 비롯한 static pod들 또한 재기동 되어진다.
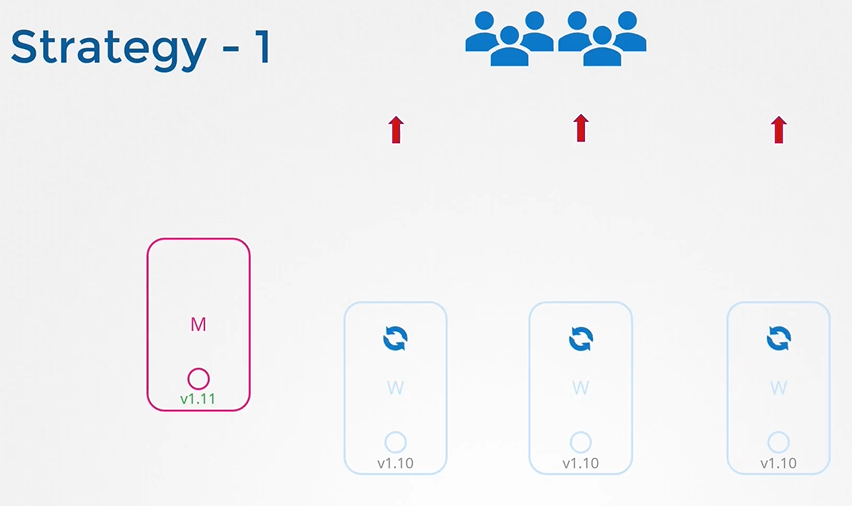
Worker Node 업그레이드 하기
Worker Node는 실제 서비스가 가동되어지는 Pod가 있는 Node이다. 업그레이드는 즉 일시적인 서비스 다운을 의미하기에 Node Upgrade 전략을 확인할 필요가 있다.
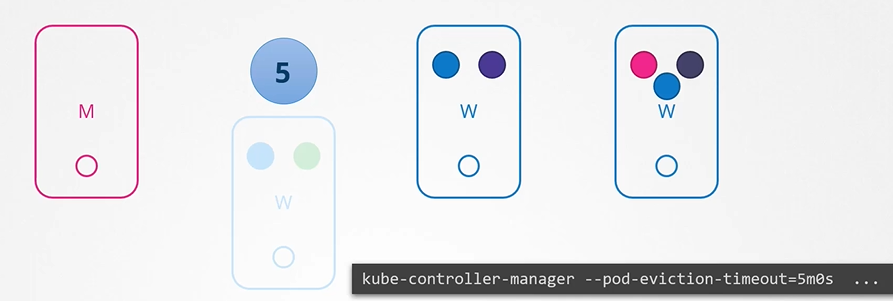
만약 Node에 다양한 Pod가 기동된 상태에서 Node가 작동불가 상태가 된다면 시스템은 5분간 해당 Node에 Pod들을 유지한다.
그 시간동안 replica가 관리하는 pod들은 다른 node로 재기동하지 않고 대기하고 있지만, 해당 시간이 초과된다면 replica로 관리되는 pod들은 다른 node에서 새롭게 재기동 되어진다. 단, 일반 pod들은 삭제되고 완전히 사라진다.
만약 Node의 정비를 이유로 해당 Node가 일정시간 서비스 지장 없이 무결한 상태로 중지될 필요가 있다면? drain명령어를 사용한다.
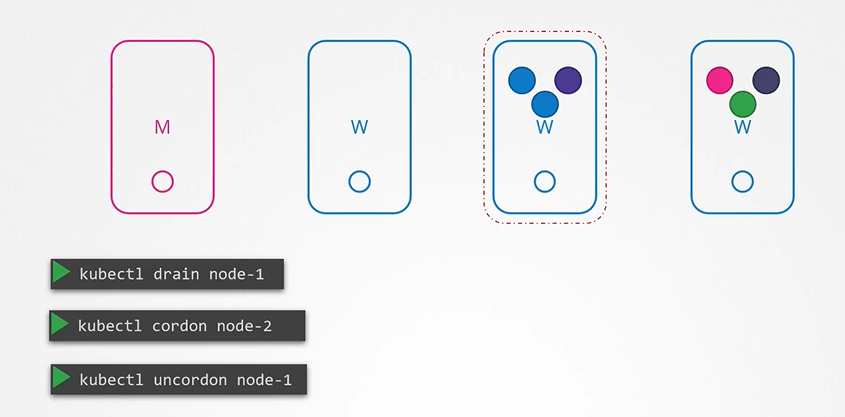
drain명령어 사용시 deployment가 관리하지 않아도 해당 node의 pod들은 다른 node에서 재기동 되어지며, 해당 node에는 스케줄러가 pod를 스케줄링하지 않는다.
drain명령어 이외에도, cordon 명령어와 uncordon 이 있는데 cordon은 해당 node에 pod들을 지금 당장 옮기지는 않지만 새로운 pod가 이 node에서 스케줄링 되지 않도록 설정하며 uncordon은 drain 또는 cordon 상태여 스케줄링 되지 않은 node를 다른 pod들도 스케줄링 가능하도록 lock을 해제하는 명령어이다.
이를 바탕으로 worker node를 업그레이드 하는 방식에는 하나의 Node를 drain시키고 kubeadm과 kubelet을 업그레이드 하는 방식이 주로 사용된다.
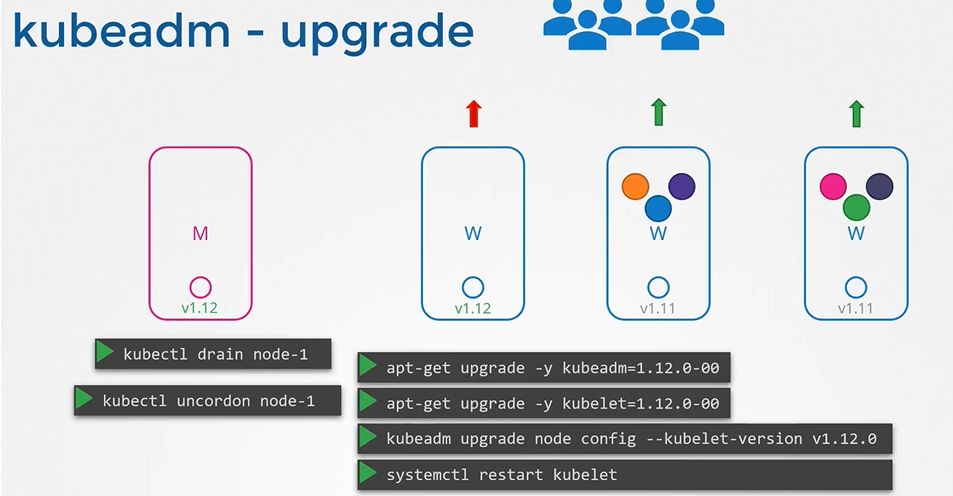
업그레이드가 정상적으로 끝났다면 uncordon을 반드시 해줘야한다.
worker node 하나를 down 시키고 하는것보단, 새로운 업그레이드 된 Node를 하나 기동시키고 하나의 구 node를
drain시켜서 점진적으로 새로운 Node들로 대체되게 하는 방식도 존재한다!